|
Subject: RE: [xsl] Asian, UTF-8, markup, extensions and d-o-e From: "Michael Kay" <michael.h.kay@xxxxxxxxxxxx> Date: Fri, 31 May 2002 09:52:11 +0100 |
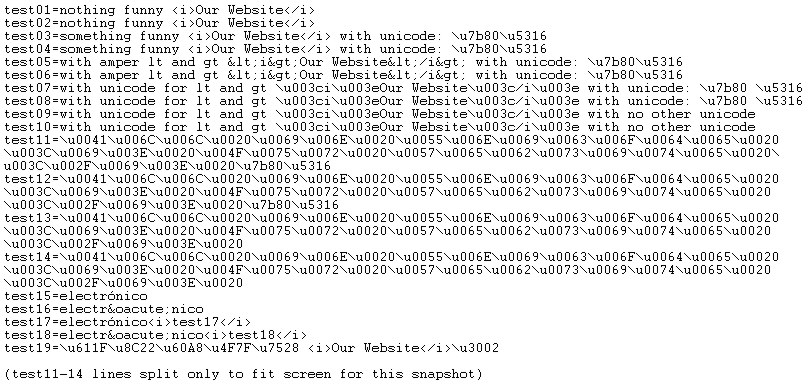
Sorry to drop the ball on this thread. I've posted a reply on the Saxon forum at https://sourceforge.net/forum/forum.php?thread_id=681805&forum_id=94027 The bottom line is that I can't reproduce the problem from the information you've given me: it works for me. But I'm afraid I don't really understand what your Java application is doing with these HashMaps. Michael Kay > -----Original Message----- > From: owner-xsl-list@xxxxxxxxxxxxxxxxxxxxxx > [mailto:owner-xsl-list@xxxxxxxxxxxxxxxxxxxxxx] On Behalf Of > Frikkie Swardt > Sent: 30 May 2002 21:58 > To: XSL-List@xxxxxxxxxxxxxxxxxxxxxx > Subject: [xsl] Asian, UTF-8, markup, extensions and d-o-e > > > > > This was posted at Sourceforge, Saxon. I got one reply but > none since May 22. I'm hoping someone on this list may be > able to assist. > > We are using Saxon 6.5 (I tried with 6.5.2; same results) > I am trying to display chinese(and others) with HTML markup. > The text gets loaded in a HashMap The text contains html > markup (break, color, class etc) It appears the > disable-output-escaping="yes" has no affect on the "<" and > ">" when there is unicode with a value above 255 in the text. > > sample HashMap for en: > label.test1=Simplified > label.test2=Traditional > label.test3=Accommodation > label.test4=Thank you for using <i>Our Website</i> > > sample HashMap for zh_CN: > label.test1=\u7b80\u5316 > label.test2=\u4f20\u7edf > label.test3=\u4F4F\u5BBF > label.test4=\u611F\u8C22\u60A8\u4F7F\u7528 <i>Our Website</i>\u3002 > > output statement: > <xsl:output method="html" indent="no" encoding="iso-8859-1" > saxon:character-representation="entity;entity" /> native, > entity, decimal or hex produce the same results on markup text. > > We call a custom extension (not saxon extension) to get the > text: <xsl:value-of disable-output-escaping="yes" > select="java:getMessage($vtExtension,$locale,string('label.test4'))"/> > > On label.test4 I expected to see Our Website in italics, but > instead I saw the markup. It never works without > disable-output-escaping="yes" It only shows the markup if the > text contains unicode for characters with values higher than > 255. (non-ASCII) > > So, I'm looking for a solution where I can use both the > unicode and markup, and still use the java extension to read > the HashMap. > > some other results: > > (snapshots at http://frik.50megs.com/xsl/thetext.jpg and > http://frik.50megs.com/xsl/theresult.jpg) > Text: > test01=nothing funny <i>Our Website</i> > test02=nothing funny <i>Our Website</i> > test03=something funny <i>Our Website</i> with unicode: > \u7b80\u5316 test04=something funny <i>Our Website</i> with > unicode: \u7b80\u5316 test05=with amper lt and gt > <i>Our Website</i> with unicode: \u7b80\u5316 > test06=with amper lt and gt <i>Our Website</i> > with unicode: \u7b80\u5316 test07=with unicode for lt and gt > \u003ci\u003eOur Website\u003c/i\u003e with unicode: \u7b80 > \u5316 test08=with unicode for lt and gt \u003ci\u003eOur > Website\u003c/i\u003e with unicode: \u7b80 \u5316 test09=with > unicode for lt and gt \u003ci\u003eOur Website\u003c/i\u003e > with no other unicode test10=with unicode for lt and gt > \u003ci\u003eOur Website\u003c/i\u003e with no other unicode > test11=\u0041\u006C\u006C\u0020\u0069\u006E\u0020\u0055\u006E\ > u0069\u0063\u006F\u0064\u0065\u0020\u003C\u0069\u003E\u0020\u0 > 04F\u0075\u0072\u0020\u0057\u0065\u0062\u0073\u0069\u0074\u006 > 5\u0020\u003C\u002F\u0069\u003E\u0020\u7b80\u5316 > > test12=\u0041\u006C\u006C\u0020\u0069\u006E\u0020\u0055\u006E\ > u0069\u0063\u006F\u0064\u0065\u0020\u003C\u0069\u003E\u0020\u0 > 04F\u0075\u0072\u0020\u0057\u0065\u0062\u0073\u0069\u0074\u006 > 5\u0020\u003C\u002F\u0069\u003E\u0020\u7b80\u5316 > > test13=\u0041\u006C\u006C\u0020\u0069\u006E\u0020\u0055\u006E\ > u0069\u0063\u006F\u0064\u0065\u0020\u003C\u0069\u003E\u0020\u0 > 04F\u0075\u0072\u0020\u0057\u0065\u0062\u0073\u0069\u0074\u006 > 5\u0020\u003C\u002F\u0069\u003E\u0020 > > test14=\u0041\u006C\u006C\u0020\u0069\u006E\u0020\u0055\u006E\ > u0069\u0063\u006F\u0064\u0065\u0020\u003C\u0069\u003E\u0020\u0 > 04F\u0075\u0072\u0020\u0057\u0065\u0062\u0073\u0069\u0074\u006 > 5\u0020\u003C\u002F\u0069\u003E\u0020 > > test15=electrónico > test16=electrónico > test17=electrónico<i>test17</i> test18=electrónico<i>test18</i> > test19=\u611F\u8C22\u60A8\u4F7F\u7528 <i>Our Website</i>\u3002 > > > Result: (yes/no refers to disable-output-escaping) > test01 yes = nothing funny Our Website > test02 no = nothing funny <i>Our Website</i> > test03 yes = something funny <i>Our Website</i> with unicode: > ?? test04 no = something funny <i>Our Website</i> with > unicode: ?? test05 yes = with amper lt and gt <i>Our > Website</i> with > unicode: ?? > test06 no = with amper lt and gt <i>Our Website</i> with > unicode: ?? > test07 yes = with unicode for lt and gt <i>Our Website</i> > with unicode: ? ? test08 no = with unicode for lt and gt > <i>Our Website</i> with unicode: ? ? test09 yes = with > unicode for lt and gt Our Website with no other unicode > test10 no = with unicode for lt and gt <i>Our Website</i> > with no other unicode test11 yes = All in Unicode <i> Our > Website </i> ?? test12 no = All in Unicode <i> Our Website > </i> ?? test13 yes below 255 = All in Unicode Our Website > test14 no below 255 = All in Unicode <i> Our Website </i> > test15 yes = electrónico test15 no = electrónico test16 yes = > electrónico test16 no = electrónico test17 yes = > electrónicotest17 test17 no = electrónico<i>test17</i> test18 > yes = electrónicotest18 test18 no = > electrónico<i>test18</i> test19 no = ????? <i>Our > Website</i>? test19 yes = ????? <i>Our Website</i>? > > > > > Michael Kay stated: > The XSLT spec says that it is an error to output a character > not available in the chosen encoding with > disable-output-escaping="yes". The processor is allowed to > signal the error, or to recover by ignoring the d-o-e="yes" > attribute. You are using encoding="iso-8859-1", therefore > outputting characters above 256 is only possible by using > character references. If you use encoding="utf-8", it should > work fine. > > So I tried what Michael suggested, but it produces a > different result, still undesireable. When using > encoding="UTF-8" , the markup works with d-o-e="yes", but > then the asian characters comes in different. They come in as > single characters, and from what I could see (viewed with a > hex viewer) is that it drops the first byte. Example (test3/4): > characters: \u7b80\u5316 > with UTF-8 and d-o-e="yes", I get x'8016' (non-displayable) > I tried with saxon:character-representation as native, > entity, hex and decimal. All have the same results. > > > snapshots at: > http://frik.50megs.com/xsl/theresultutf8.jpg > http://frik.50megs.com/xsl/viewsource.jpg > > > > Thanks for any light you can put on this subject. > > XSL-List info and archive: http://www.mulberrytech.com/xsl/xsl-list > XSL-List info and archive: http://www.mulberrytech.com/xsl/xsl-list
| Current Thread |
|---|
|
| <- Previous | Index | Next -> |
|---|---|---|
| Re: [xsl] Asian, UTF-8, markup, ext, David Carlisle | Thread | [xsl] & not processed correctly, Zack Brown |
| AW: [xsl] Finding node having maxim, Pfitzner, Jan | Date | [xsl] Less than comparison has chan, Vladimir Stanciu |
| Month |
{kind=link}
{kind=link}
{kind=link}
{kind=link}